Solving the rate-limiting steps of drug discovery
Drug development is arduous and lengthy. That difficulty is reflected in the price of medicine as high drug prices. But the story would be very different and relief brought to all stakeholders if the rate limiting step in the drug discovery process can be solved.


Drug development is arduous and lengthy. That difficulty is reflected in the price of medicine as high drug prices are a direct corollary of the burdensome challenges companies must overcome to conceive of a medicine and get it through research and development into the hands of patients. But the story would be very different and relief brought to all stakeholders if the rate limiting step in the drug discovery process can be solved.
The apparent reasons for the onerousness of drug development include delivery, development, toxicology, manufacturing and regulatory burdens (at least from the perspective of industry). While it's true that these are contributing factors, many of these are oftentimes operational problems that can be expedited through better execution and planning, and recent advances in drug delivery science are easing delivery challenges.
The crucial rate limiting step of drug discovery is coming up with the genetic explanation (or disease mechanism) and thus predictive model for a cure. This process is typically left up to academic labs who, with funding from federal agencies and after years of toil, would provide a predictive model for a disease including potential targets. The pharmaceutical industry then takes it from there and enterprises to develop therapeutic modalities against the targets identified by academic groups.
And thus rolls on the drug discovery wheel, with industry depending on the disease mechanism elucidation performed by academia before it can move forward. This is a simplification. For a more detailed look at the contributions of academia and industry to the discovery of new therapeutics, consult this paper (summary figure below).
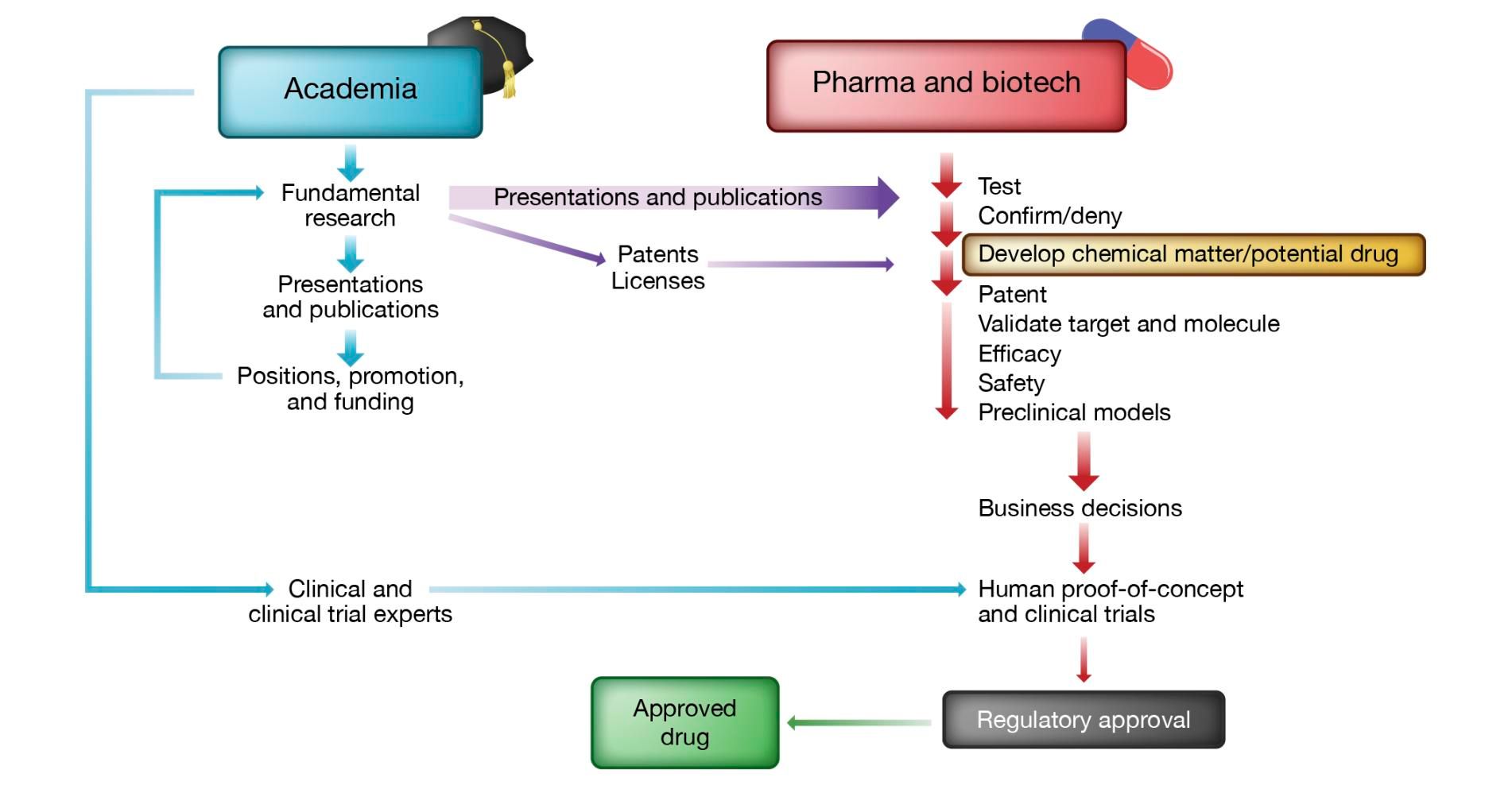
Given the high risk nature of the disease mechanism elucidation side, industry has practically abandoned it, preferring instead to embark on reductionist strategies that see them pursue the same old targets with yet another therapeutic modality. But, two key facts should have biotech and pharma players correcting course:
1. There is evidence that even a modicum of genetic support confers to targets more than twice the likelihood of clinical sucess over targets that lack such genetic backing.
2. The slight increase in FDA approvals starting from 2012 came as a result of the biotech industry's increasing focus on rare diseases and cancers with better understood genetics.
Point 2 above is from this paper, which cuts through the noise to examine the key problem that is stifling drug discovery. It is a strong indictement of the current approach. Here are the authors in their own words:
12345 DNA sequencing has become over a billion times faster since the first genome sequences were determined in the 1970s 67 aiding the identification of new drug targets It now takes at least three orders of magnitude fewer man-hours to calculate three-dimensional protein structure via x-ray crystallography than it did 50 years ago 89 and databases of three-dimensional protein structure have 300 times more entries than they did 25 years ago109 facilitating the identification of improved lead compounds through structure-guided strategies High throughput screening (HTS) has resulted in a tenfold reduction in the cost of testing compound libraries against protein targets since the mid-1990s 11 Added to this are new inventions (such as the entire field of biotechnology computational drug design and screening and transgenic mice) and advances in scientific knowledge (such as an understanding of disease mechanisms new drug targets biomarkers and surrogate endpoints)”
in contrast [12], many results derived with today’s powerful tools appear irreproducible13141516 today’s drug candidates are more likely to fail in clinical trials than those in the 1970s 1718 R&D costs per drug approved roughly doubled every ~9 years between 1950 and 2010 1920121 some now even doubt the economic viability of R&D 2223
121242526
there has been too much enthusiasm for highly reductionist [predictive model]s with low [predictive validity] 267925808174821838474 good reductionist models have been difficult to produce, identify, and implement [85] [82], so there has been a tendency to use bad ones instead; particularly for common diseases868387 After all, brute-force efficiency metrics are relatively easy to generate, to report up the chain of command, and to manage. The [predictive validity] of a new screening technology or animal [predictive model], on the other hand, is an educated guess at best. 65
the rate of creation of valid and reliable [predictive model]s may be the major constraint on industrial R&D efficiency today 1692
We could not agree more with many of the points raised by the paper's authors. Overcoming the rate limiting step of drug discovery (i.e., "lack of valid and reliable predictive models") allows for faster time to market, lower development costs, and benefiting from regulatory acceleration programs such as the FDA's fast track and breakthrough designations. Not only that, but another reason to focus on actionable, genetically-defined predictive models is because they are required for precision medicine where the traditional reductionist approach is obviously ill suited.
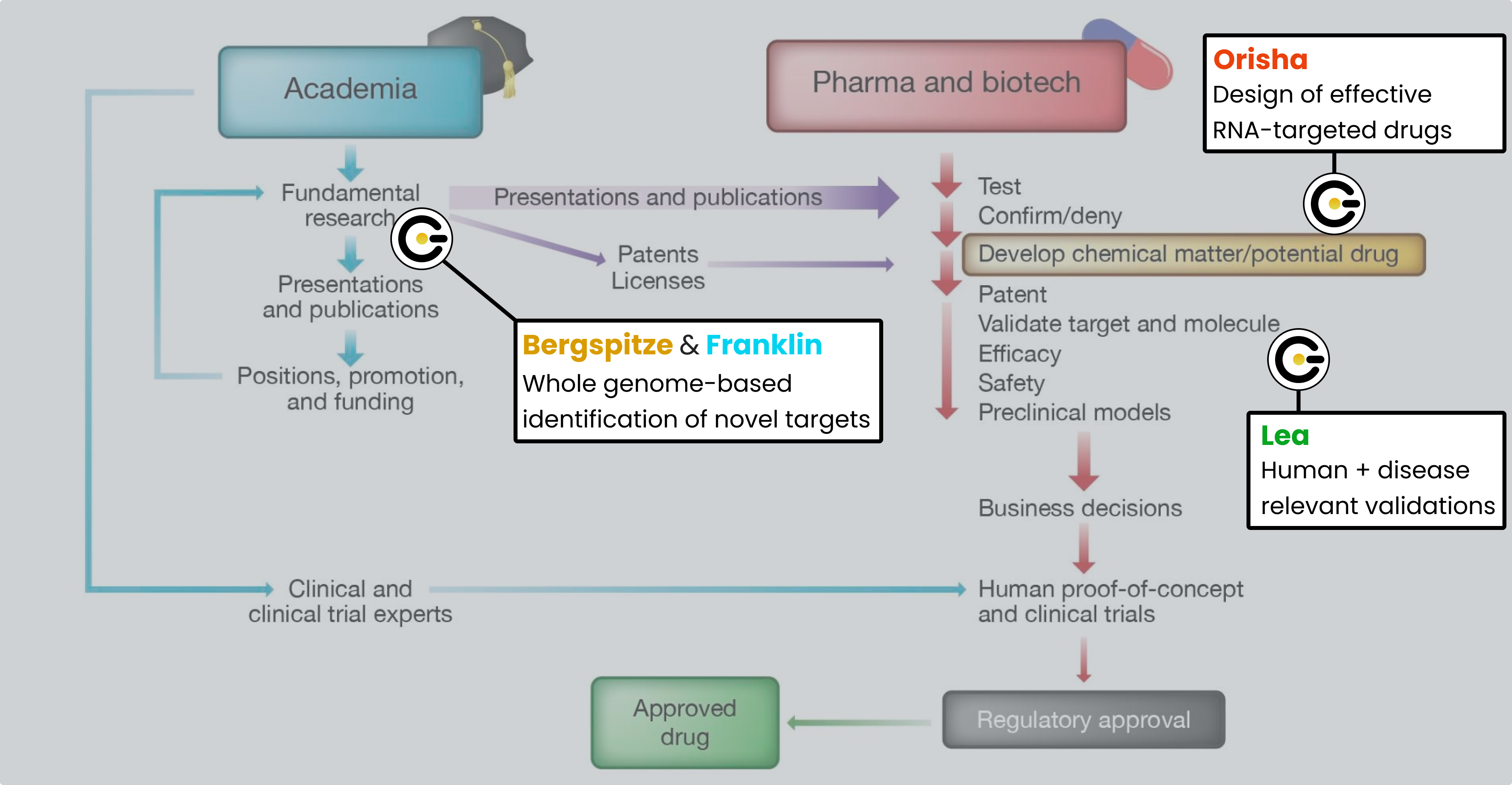
It's for these reasons that we pioneered the Genetic Intelligence platform, to blow away the rate limiting step of drug discovery and take chance out of the process with validated, reproducible, whole genome-derived predictive models for disease. Here's how it works:
Layer 1 of our platform is Bergspitze, the biology-aware AI stack that tames the noise of the whole genome to pinpoint the genetic positions causal of disease, even when sample sizes are small.
Layer 2 of our platform is Franklin, the interpretation infrastructure that takes in the output from Bergspitze and provides a coherent etiology model for the disease with awareness of alternative etiologies advanced in the literature. Importantly, Franklin confirms targets to leverage for a cure, whether the original genetic lesion output by Bergspitze or derivative nodes (i.e., RNA, protein) in the attendant biological pathway.
Layer 3 of our platform is Orisha, the prediction infrastructure that for each target confirmed by Franklin provides a computationally-validated molecule to drug the target's transcript RNA at the sequence (with oligonucleotides) or at the structure (with small molecules).
Layer 4 of our platform is Lea, the testing field that leverages patient-derived iPSC (stem cell) assays to confirm early biological efficacy of the candidates produced by the computational layers. The importance of using patient stem cells assays (versus murine models which are used to confirm safety) cannot be overstated and is explored in another post.